If you’ve ever tried to make sense of a stack of CVs, you’ll know it’s a chaotic mess of formatting styles, bullet points, and scattered info. You might spot a great candidate on page three, lose track by page five, and forget who worked with whom. Now imagine structuring all that—automatically—and turning it into something you can query, explore, and build AI on top of.
That’s exactly what I’ve been experimenting with: using Google’s Gemini to parse CVs and Neo4j to store that data in a graph format.
Let me walk you through how it works.
Why Use Graphs for CVs?
Traditional databases are great, but when you’re dealing with relationships like:
- Who worked where?
- What skills did they use?
- What projects did they do for which clients?
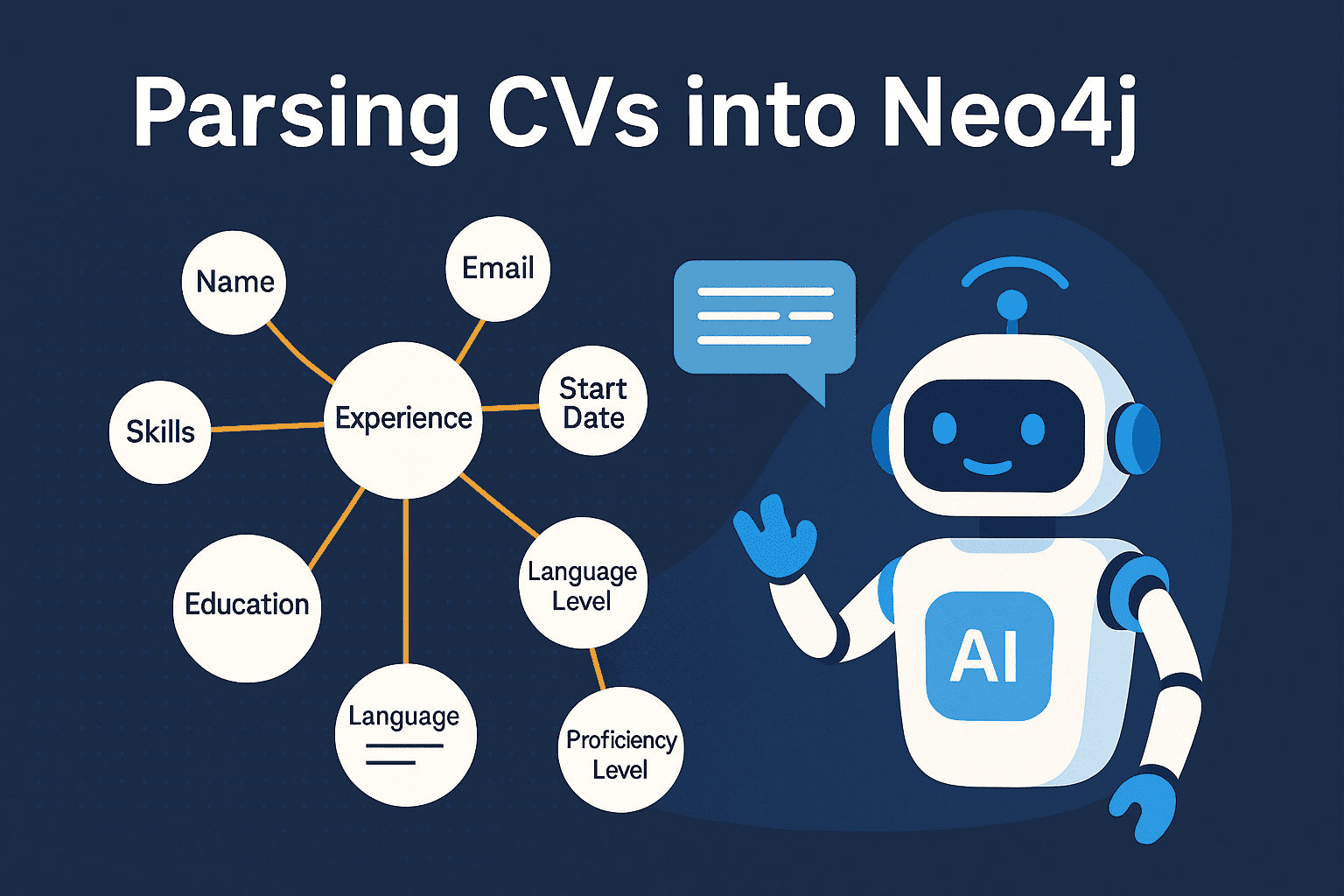
A graph just makes more sense. Neo4j allows you to store this kind of data with natural relationships like:
(Person)-[:HAS_SKILL]->(Skill)
(Person)-[:HAS_POSITION]->(Position)-[:AT_COMPANY]->(Company)
(Position)-[:WORKED_ON]->(Project)-[:FOR_CLIENT]->(Company)This setup gives you the flexibility to ask complex questions later—more on that in a bit.
From Unstructured PDF to Structured Graph
Here’s how I turned a raw PDF CV into a structured, queryable graph:
- Extract the Text: I use PyMuPDF to get plain text from PDF CVs. It’s fast, lightweight, and works surprisingly well.
- Parse with Gemini: Google’s Gemini model helps extract structured data from the unstructured blob. I send the text with a carefully crafted prompt asking for:
- Name, email, LinkedIn, GitHub
- Work experience (with start/end dates, titles, responsibilities, and even which projects were done for which clients)
- Skills, languages, education
- Push to Neo4j: Once I have the structured JSON, I insert it into Neo4j using the official driver. Each CV becomes a living, connected data model.
The Code
Here’s the good part. I’ve made the full Python script available so you can try this yourself. It reads a PDF, parses it with Gemini, and saves the data in Neo4j in a fully structured way.
It’s clean, extensible, and you’ll find it easy to modify depending on your needs. Get the code at this GIST and keep reading below for the juice.
The main part that does all the heavy lifting is the prompt we send to Gemini, along with the extracted raw text from each CV.
Why prompting matters
The real magic behind this script lies in the prompt sent to Gemini. Parsing CVs isn’t just about extracting keywords—it’s about understanding the context, handling inconsistencies, and mapping free-form content into a structured format that AI can reason over.
CVs vary wildly. Some candidates write detailed project descriptions, others use bullet points, and formatting is all over the place. This prompt is carefully crafted to:
- Normalize the chaos of different CV styles into a consistent JSON schema.
- Guide the AI to separate past vs. current roles based on the company you’re focused on.
- Identify hidden context, like when someone works for a client under another company (e.g., a consultant working at SmartUp on behalf of Vodafone).
- Extract semantically rich data, like skillsets, education timelines, and languages—even if they’re buried in paragraphs.
By explicitly defining what fields to extract, how to structure nested information like responsibilities and projects, and setting strict output boundaries (like returning only the JSON object), the prompt acts like a contract between you and the model.
This makes the parser surprisingly robust, even when faced with messy, non-standard CVs.
# --- Gemini Parsing Function ---
def parse_cv_with_gemini(cv_text):
"""Sends CV text to Gemini API and requests structured JSON output."""
if not cv_text:
logging.warning("CV text is empty, skipping Gemini parsing.")
return None
# ** IMPORTANT: Craft a detailed prompt requesting the specific JSON structure **
# This prompt needs refinement based on testing with your actual CVs.
prompt = f"""
Parse the following CV text and extract the information into a JSON object.
The JSON object should strictly follow this structure:
{{
"name": "Full Name",
"email": "email @ address",
"phone": "+1234567890",
"linkedin_url": "Optional LinkedIn Profile URL",
"github_url": "Optional GitHub Profile URL",
"profile_summary": "A brief summary or objective statement from the CV.",
"skills": ["Skill 1", "Skill 2", "Technology 3"],
"experience": [
{{
"title": "Job Title",
"company": "Company Name",
"start_date": "YYYY-MM or textual description like 'Jan 2020'",
"end_date": "YYYY-MM, 'Present', or textual description",
"responsibilities": [
"Responsibility description 1.",
"Responsibility description 2."
],
// *** Crucial flags ***
"is_past_experience": true, // true if this job was BEFORE {COMPANY_NAME}, false otherwise
"client_name": "Client Company Name OR null" // If the company is {COMPANY_NAME} AND the description mentions working FOR a specific client, put the client's name here. Otherwise null.
}}
// ... more experience objects
],
"education": [
{{
"university": "University Name",
"degree": "Degree Name (e.g., BSc Computer Science)",
"field_of_study": "Field (e.g., Software Engineering)", // Optional refinement
"start_date": "YYYY or textual description",
"end_date": "YYYY, 'Expected Grad YYYY', or textual description"
}}
// ... more education objects
],
"languages": [
{{
"language": "Language Name",
"level": "Proficiency Level (e.g., Native, Fluent, A2, Basic)"
}}
// ... more language objects
]
}}
**Instructions & Clarifications:**
- Identify the main current employer as "{COMPANY_NAME}". Any experience listed *before* the start date of the first role at "{COMPANY_NAME}" should have "is_past_experience": true. Roles *at* "{COMPANY_NAME}" should have "is_past_experience": false.
- For roles at "{COMPANY_NAME}", if the responsibilities clearly state the work was *for* another company (e.g., "Developed a system for Client X", "Project for Client Y"), extract "Client X" or "Client Y" into the "client_name" field for that specific experience entry. Otherwise, "client_name" should be null.
- Extract dates as accurately as possible. If exact YYYY-MM is not available, use the text provided (e.g., "Summer 2023"). Use "Present" for ongoing roles.
- Consolidate skills into a single list of strings.
- Extract languages and their proficiency levels.
- Ensure the entire output is ONLY the JSON object, nothing else before or after.
**CV Text:**
--- START CV TEXT ---
{cv_text}
--- END CV TEXT ---
**JSON Output:**
"""
try:
logging.info("Sending request to Gemini API...")
# Use generate_content with generation_config for JSON mode if available/preferred
# response = model.generate_content(prompt, generation_config=genai.types.GenerationConfig(response_mime_type="application/json"))
# Or simpler method:
response = model.generate_content(prompt)
# Clean potential markdown code fences json ...
cleaned_response_text = re.sub(r'^json\s*|\s*$', '', response.text.strip(), flags=re.MULTILINE)
logging.info("Received response from Gemini.")
# print("Gemini Raw Response Text:", cleaned_response_text) # Debugging
# Parse the JSON response
parsed_json = json.loads(cleaned_response_text)
logging.info("Successfully parsed JSON response from Gemini.")
return parsed_json
except json.JSONDecodeError as json_err:
logging.error(f"Failed to decode JSON from Gemini response: {json_err}")
logging.error(f"Gemini raw response was:\n{response.text[:500]}...") # Log partial response
return None
except Exception as e:
logging.error(f"Error during Gemini API call or processing: {e}", exc_info=True)
# Log response text if available and exception happened after getting response
if 'response' in locals() and hasattr(response, 'text'):
logging.error(f"Gemini raw response text was:\n{response.text[:500]}...")
return NoneWhat You Can Do With This
Now, I haven’t added the full AI agent layer yet—but it’s coming. Soon, I’ll be using Google’s Gen AI Toolbox for Databases to add a query interface over the graph, so you can ask questions like:
- “What projects did EmployeeName do for CompanyName?”
- “Which engineers at CompanyName worked on AI products after 2022?”
- “Who has Python, Spanish, and experience with telecom clients?”
For now, though, this script gets you a long way. It’s already a big step toward turning resumes into insights.
Notice: Follow Part2 to read about the mutli-run AI Agent
Try It Yourself
This is the kind of tooling I wish I had years ago when managing teams or reviewing candidate lists. It’s fast, scalable, and graph-native from the start.
If you’re building something similar or just curious, feel free to reach out or share feedback. And stay tuned—I’ll be diving into the AI agent side soon.
See you in the graph.

Comments are closed